Assignment 6: Regression Analysis
Goals of Assignment 6
Running regression analyses in SPSS
Regression output interpretation and prediction
Manipulate data in Excel and join to ArcGIS
Mapping standardized residuals in ArcGIS
Connect statistics to spatial outputs
Part I
Introduction
A study was performed in a town and the resultant data was used by the local news station to make the claim that, as the number of children that received free lunches increased, the crime rate in the town also increased. This claim seems to be unreasonable/misinformed and the type of data that could be used by political leaders in efforts to reduce expenditures on free lunch programs. There has been a tendency to reduce social spending in several states (primarily so-called "red states") based on misinterpreted statistics. In order to determine if there is a linear relationship between these variables (free lunch and crime rates), and what the crime rate would be if an area of town had 30% of its children receiving free lunch would be, a statistical analysis is required. Statistical analyses are useful methods to use to see if the report made by the news station has merit.
Methods
An Excel file of the data used by the local news station was provided by Dr. Ryan Weichelt of the University of Wisconsin- Eau Claire. A regression analysis, a statistical test that investigates the relationship between two variables; the effect of an independent variable, x, on a dependent variable, y, was performed for this data. It is a predictive model that enables us to understand the effect of the IV on the DV. It does not, however, allow us to make causal inferences but does allow us to investigate potential causes.
The hypotheses for this analysis are as follows:
Null Hypothesis: There is no linear relationship between crime rates and percentage of kids that receive free lunches
Alternative Hypothesis: There is a linear relationship between crime rates and percentage of kids that receive free lunches.
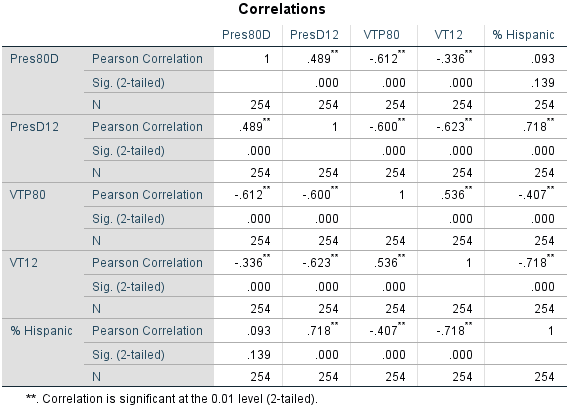
Microsoft Excel was first used to create a scatterplot of the linear relationship between crime rates and percentage of children receiving free lunches to create a visual representation of this relationship. Using IBM Statistics SPSS 24, with crime rates (crimes per 100,000 population) set as the dependent variable, and the percentage of children receiving free lunches (PerFreeLunch) as the independent variable, both a coefficient of determination and standard error of the estimate were derived. The coefficient of determination (R Square) is a numeric value that represents how much of the variation in the dependent variable (DV) that is explained by the independent variable (IV). It is similar to a correlational analysis in that the higher the value of this number the stronger the relationship (see Assignment 5). The standard error of the estimate (SEE) is the total of the standard deviations of the residuals. The smaller this number, the more accurate the prediction of the effects of IV on the DV. A regression equation, Y = a + bx, where a is the constant (dependent variable) and b is the slope of the line (also called the regression coefficient) was also created. The slope of the line shows the responsiveness of the dependent variable as a function of change in the independent variable (Figure 1).
Results
Figure 1 is the visual relationship between the IV and the DV with a trendline in place. Figure 2 represents the results of this regression analysis. There is a significant positive (as the slope of our line is positive) relationship between crime rate and the percentage of children receiving free lunches, as our observed significance and trendline show; .005 is less than .05. We reject the null hypothesis as there is a linear relationship between the independent and dependent variables. To answer the question of crime rates in an area of town given the percentage of children on free lunched a formula was developed. The formula for this analysis is y = 21.819 + 1.685x, using the constant (dependent variable) 21.819 and the independent variable, PerFreeLunch, as seen in Figure 2. If an area of town had 30% of its children receiving free lunches to corresponding crime rate would be 72.369 per 100,000 population.



Conclusion
The news station is technically correct in that there is a significant linear relationship between crime rate and the percentage of children receiving free lunches. This is misleading, however, as our R Square value of .173 shows that our independent variable, percentage of children receiving free lunch, only explains 17.3% of the variation observed in our dependent variable, crime rate. The Standard Error of the Estimate of 96.6072 suggests that the accuracy of our predictive model is very weak as the SEE is an approximation of the magnitude of the residuals. Residuals represent the amount of deviation of each point from the regression line
Part II
Part I
Introduction
A study was performed in a town and the resultant data was used by the local news station to make the claim that, as the number of children that received free lunches increased, the crime rate in the town also increased. This claim seems to be unreasonable/misinformed and the type of data that could be used by political leaders in efforts to reduce expenditures on free lunch programs. There has been a tendency to reduce social spending in several states (primarily so-called "red states") based on misinterpreted statistics. In order to determine if there is a linear relationship between these variables (free lunch and crime rates), and what the crime rate would be if an area of town had 30% of its children receiving free lunch would be, a statistical analysis is required. Statistical analyses are useful methods to use to see if the report made by the news station has merit.
Methods
An Excel file of the data used by the local news station was provided by Dr. Ryan Weichelt of the University of Wisconsin- Eau Claire. A regression analysis, a statistical test that investigates the relationship between two variables; the effect of an independent variable, x, on a dependent variable, y, was performed for this data. It is a predictive model that enables us to understand the effect of the IV on the DV. It does not, however, allow us to make causal inferences but does allow us to investigate potential causes.
The hypotheses for this analysis are as follows:
Null Hypothesis: There is no linear relationship between crime rates and percentage of kids that receive free lunches
Alternative Hypothesis: There is a linear relationship between crime rates and percentage of kids that receive free lunches.
Microsoft Excel was first used to create a scatterplot of the linear relationship between crime rates and percentage of children receiving free lunches to create a visual representation of this relationship. Using IBM Statistics SPSS 24, with crime rates (crimes per 100,000 population) set as the dependent variable, and the percentage of children receiving free lunches (PerFreeLunch) as the independent variable, both a coefficient of determination and standard error of the estimate were derived. The coefficient of determination (R Square) is a numeric value that represents how much of the variation in the dependent variable (DV) that is explained by the independent variable (IV). It is similar to a correlational analysis in that the higher the value of this number the stronger the relationship (see Assignment 5). The standard error of the estimate (SEE) is the total of the standard deviations of the residuals. The smaller this number, the more accurate the prediction of the effects of IV on the DV. A regression equation, Y = a + bx, where a is the constant (dependent variable) and b is the slope of the line (also called the regression coefficient) was also created. The slope of the line shows the responsiveness of the dependent variable as a function of change in the independent variable (Figure 1).
Figure 1 is the visual relationship between the IV and the DV with a trendline in place. Figure 2 represents the results of this regression analysis. There is a significant positive (as the slope of our line is positive) relationship between crime rate and the percentage of children receiving free lunches, as our observed significance and trendline show; .005 is less than .05. We reject the null hypothesis as there is a linear relationship between the independent and dependent variables. To answer the question of crime rates in an area of town given the percentage of children on free lunched a formula was developed. The formula for this analysis is y = 21.819 + 1.685x, using the constant (dependent variable) 21.819 and the independent variable, PerFreeLunch, as seen in Figure 2. If an area of town had 30% of its children receiving free lunches to corresponding crime rate would be 72.369 per 100,000 population.

Figure 1: Scatterplot of Relationship Between Crime Rates and Percentage of Kids Recieving Free Lunches


Figure 2: Results from Regression Analysis, Crime Rate (Per 100,000) as Dependent Variable and Percentage of Children Receiving Free Lunches as Independent Variable
Conclusion
The news station is technically correct in that there is a significant linear relationship between crime rate and the percentage of children receiving free lunches. This is misleading, however, as our R Square value of .173 shows that our independent variable, percentage of children receiving free lunch, only explains 17.3% of the variation observed in our dependent variable, crime rate. The Standard Error of the Estimate of 96.6072 suggests that the accuracy of our predictive model is very weak as the SEE is an approximation of the magnitude of the residuals. Residuals represent the amount of deviation of each point from the regression line
Part II
Introduction
The City of Portland wants an assessment on whether or not the response times for 911 calls are adequate. The city is also interested in the possible variables that may help to explain as to which areas of the city experience higher call volumes. A new hospital is being proposed and its potential location and size of emergency room depend upon the determination of factors that can result in high call volumes. The completion of this analysis can help in determining the location of where the hospital is built by a company contracted by the city; the size of the emergency room is beyond the scope of this analysis.
Methods
Methods
All data was supplied by the City of Portland for use in this analysis and consisted of an Excel file with several variables and a census tract shapefile of the City of Portland. The dependent variable for this analysis is the number of 911 calls and three out of the following list of variables were chosen:
Jobs
Renters
LowEduc (Number of people with no HS Degree)
AlcoholX (alcohol sales)
Unemployed
ForgnBorn (Foreign Born Pop)
Med Income
CollGrads (Number of College Grads)
The number of people with no high school diploma, jobs, and median income were chosen for analysis. Each variable was run through a regression analysis in SPSS; each of the chosen variables acted as the independent variable and the number of calls per census tract acted as the dependent variable in each analysis.
IV 1: Number of people with no HS degree
IV 2: Jobs
IV 3: Median income
DV: Number of calls per census tract
Null Hypotheses: There is no linear relationship between the number of 911 calls and number of people with no high school degree, job type, and median income.
Alternative Hypotheses: There is a linear relationship between the number of 911 calls and the number of people with no high school degree, job type, and median income.
Three linear regression analyses were run utilizing IBM Statistics SPSS 24. A chloropleth map depicting call volumes by census tract and another representing the standardized residuals of the numbers of people with no high school degree and number of 911 calls were then produced in ArcGIS. The standardized residuals map used the number of people without high school diplomas as the relationship between this variable and 911 call volume had the largest R Square value with a significant result. These standardized residuals were created in ArcGIS, using spatial statistics. Figure 7 is a portrayal of the standardized residuals using the Ordinary Least Squares (OLS) method where a line is placed onto the data point set in a way that minimizes the vertical distance of the sum of squares from the line. A standardized residual allow the residuals to be compared on a distribution where a point falls in terms of standard deviations from the mean, allowing meaningful comparisons to be made, i.e. the standardized residuals are z-scores that show the distance from the mean that a census tract falls.
Results
All three of the null hypotheses were rejected as all positive linear relationships between these variables had a significance of .000, which is lower than .05 (Figures 3-5). The R Squared values varied widely: the number of people without high school diplomas has an observed value of .567 (Figure 3), jobs, an observed value of .340 (Figure 4), and median income, a value of .163, (Figure 5). The effect of the number of people without high school diplomas has the greatest predictive value in that it explains 56.7% of the variance in 911 call volume, while jobs and median income have much lower predictive values, at 34% and 16.3% respectively. The following regression equations were formulated, representing the change in 911 call volume (the constant) per one unit change in the IV, represented by x.
Regression Equations:
Number of people with no HS degree and 911 calls, Y = 3.931 + .166x (Figure 3)
Jobs and 911 calls, Y = 18.640 + .007x (Figure 4)
Median income and 911 calls, Y = 61.625 + .001x (Figure 5)
The spatial representations of 911 call volume by census tract (Figure 6) and the standardized residuals of the number of people without high school diplomas and 911 call volume (Figure 7) both show patterns that a regression analysis cannot, helping us to better interpret our results. For Figure 6 the descriptive statistics are as follows: mean of 24.735632, maximum observed of 176, minimum observed of 0 (range = 176) and standard deviation of 28.418247. For Figure 7 the standard deviation of the data is .988439, with a minimum observed of -1.587459 and a maximum of 3.899492. Census tracts 60, 65, 79, and 24 are all in the higher standard deviation classes on both maps, which means that there are higher numbers of 911 calls in these areas (Figure 6) and that the higher numbers of calls is influenced by higher levels of people without high school diplomas (Figure 7). The number of 911 calls in these areas are being overestimated, which means that the IV is having an effect on the observed quantity of the DV. There is an overall general pattern of higher volumes of 911 calls concentrated in the center of Portland, where there are fewer people with high school diplomas. The areas surrounding the center of both maps show low positive to negative standard deviations; they are areas of both lower volumes of 911 calls (Figure 6) and lower numbers of people without high school diplomas (Figure 7). There is a spatial pattern associated with this data that cannot be discerned from statistical data alone.
Number of People with no HS degree


Figure 3: Regression Analysis, Number of 911 Calls, Dependent Variable, Number of People With no High School Diploma, Independent Variable
Jobs


Figure 4: Regression Analysis, Number of 911 Calls, Dependent Variable, Number of People With no High School Diploma, Independent Variable
Median Income


Figure 5: Regression Analysis, Number of 911 Calls, Dependent Variable, Median Income, Independent Variable

Figure 6: 911 Calls by Census Tract, Standard Deviation Classification Method

Figure 7: Standardized Residuals of People Without High School Diplomas and Number of 911 Calls
Conclusion
The variables (jobs, median income, and numbers of people without high school diplomas) that were chosen for predicting 911 call volumes had varying levels of effectiveness on explaining the observed changes in the quantities of the DV. The effect of the number of people without high school diplomas was the most substantial. Based on the regression analysis and the maps produced, the best place to build a hospital would be in census tract 10 (highlighted in green), as it is located in the approximate center of areas with higher numbers of 911 calls and those without high school diplomas. This would probably be modified based on the population of census tracts and suitable roadway accessibility for faster response times while maintaining larger numbers of people without high school diplomas within a minimum distance for life-saving care. Additional regression analyses of each variable and, possibly, a multiple regression, would be required to ensure that the largest number of people most likely to make 911 calls could count on adequate response times.
The variables (jobs, median income, and numbers of people without high school diplomas) that were chosen for predicting 911 call volumes had varying levels of effectiveness on explaining the observed changes in the quantities of the DV. The effect of the number of people without high school diplomas was the most substantial. Based on the regression analysis and the maps produced, the best place to build a hospital would be in census tract 10 (highlighted in green), as it is located in the approximate center of areas with higher numbers of 911 calls and those without high school diplomas. This would probably be modified based on the population of census tracts and suitable roadway accessibility for faster response times while maintaining larger numbers of people without high school diplomas within a minimum distance for life-saving care. Additional regression analyses of each variable and, possibly, a multiple regression, would be required to ensure that the largest number of people most likely to make 911 calls could count on adequate response times.